#SQL Server row lock
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Overcoming SQL Server Row Lock Contention
In the world of database management, efficiency and smooth operation are paramount. Particularly with SQL Server, one challenge that often arises is row lock contention. This issue can severely impact the performance of your database, leading to slower response times and, in severe cases, deadlocks. However, with the right strategies and understanding, overcoming this hurdle is entirely within…
View On WordPress
#database performance#deadlock prevention#lock contention solutions#SQL Server row lock#T-SQL Code Examples
0 notes
Text
An Overview of Microsoft SQL Server for Database Management
An extensive variety of applications that are associated with data analytics, business intelligence (BI), and transaction processing can be supported by Microsoft SQL Server, which is a relational database management system (RDBMS) that is utilized in corporate information technology environments. Database administrators (DBAs) and other professionals working in information technology are able to operate databases and query the data that they contain thanks to Structured Query Language (SQL), which is a standardized programming language.
SQL is the foundation upon which other relational database management systems (RDBMS) software is constructed. Transact-SQL, sometimes known as T-SQL, is the proprietary query language that Microsoft uses. SQL Server is intrinsically linked to them. Through the use of T-SQL, you are able to connect to a SQL Server instance or database, as well as communicate with other programs and tools.

Inside the architecture of SQL Server: What are the workings of SQL Server?
The basic basis upon which SQL Server is built is a table structure that adheres to the row-based model. Through the utilization of this structure, it is possible to establish connections between data items that are not only related but also placed in other tables. The usually necessary practice of storing data in many locations inside a database is rendered unnecessary as a result of this. In order to ensure that the data is accurate, the relational model also has the capability of providing relative integrity as well as additional integrity requirements.
The execution of database transactions is made more trustworthy by these checks, which are a component of a more thorough adherence to the concepts of atomicity, consistency, isolation, and durability. In other words, these checks are necessary for a more reliable execution of database transactions. In SQL Server, the Database Engine is the most fundamental component. It is responsible for managing all aspects of data storage, including access, processing, and security. As many as fifty instances of the Database Engine can be installed on a single host machine.
In addition to this, it is made up of a relational engine that processes commands and queries, as well as a storage engine that manages database files, tables, pages, indexes, data buffers, and transactions on the database. A wide range of database items, such as stored procedures, triggers, views, and other objects, are all created and executed by the Database Engine. This engine is responsible for maintaining the database. For the purpose of establishing a connection to Database Engine, it is necessary to have a client library or client tool that is functional in either a graphical user interface or a command-line interface, and that has at least one client library.
It is important to provide information regarding the instance name of the database engine system in order to achieve the establishment of a connection. Additionally, users have the right to choose whether or not they wish to provide information regarding the connection port and the protocol that is used by the network. The SQL Server Operating System, often known as SQLLOS, is situated so that it is subordinate to the Database Engine. It is SQLOS that is responsible for handling lower-level functions. In order to prevent separate versions of the database from being updated in a different manner, these characteristics include memory management, input/output (I/O) management, job scheduling, and data locking.
Above the Database Engine is a network interface layer, which is designed to make the process of exchanging requests and responses with database servers more straight forward. The Tabular Data Stream protocol, which was designed by Microsoft, is utilized and utilized by this layer. The writing of T-SQL statements at the user level, on the other hand, is under the purview of SQL Server database administrators and developers. In addition to a variety of other functions, these statements are utilized for the purpose of constructing and modifying database structures, managing data, implementing security measures, and backing up databases.
Securing SQL Server with its built-in features-
Users are able to update encrypted data without having to decrypt. There are three technologies that are included in the advanced security features that are supported in all editions of Microsoft SQL Server beginning with SQL Server 2016 Service Pack 1. These technologies are row-level security, which allows data access to be controlled at the row level in database tables; dynamic data masking, which automatically hides elements of sensitive data from users who do not have full access privileges; and row-level security.
More key security features of SQL Server include fine-grained auditing, which gathers specific information on database usage for the goal of reporting on regulatory compliance, and transparent data encryption, which encrypts data files that are kept in databases. Both of these capabilities are designed to ensure that sensitive information is protected. Microsoft also provides support for the Transport Layer Security protocol in order to guarantee the security of connections between SQL Server clients and database servers. This is done with the intention of ensuring the safety of the connections. The vast majority of the tools and other functionalities that are offered by Microsoft SQL Server are supported by Azure SQL Database, which is a cloud database service that is built on SQL Server Database Engine.
Moreover, support is provided for additional functionality. Customers have the option of running SQL Server directly on Azure through the use of an alternative approach known as SQL Server on Azure Virtual Machines. Through the use of this technology, the database management system (DBMS) on Windows Server virtual machines that are running on Azure can be configured. For the aim of transferring or extending on-premises SQL Server applications to the cloud, the Virtual Machine (VM) service is optimized. On the other hand, the Azure SQL Database is designed to be utilized in the process of developing new cloud-based applications. Additionally, Microsoft offers a data warehousing solution that is hosted in the cloud and is known as Azure Synapse Analytics.
The Microsoft SQL Server implementation that makes use of massively parallel processing (MPP) is the foundation upon which this service is constructed. Additionally, the MPP version, which was formerly a standalone product called as SQL Server Parallel Data Warehouse, is also available for use on-premises as a component of Microsoft Analytics Platform System. This version was initially produced by Microsoft. PolyBase and other big data technologies are incorporated into this system, which also incorporates the MPP version. There are a number of advanced security measures that are included in each and every edition of Microsoft SQL Server. These features include authentication, authorization, and encryption protocols. A user's identity can be verified by the process of authentication, which is done performed by Windows and SQL Server, in addition to Microsoft Entra ID.
The aim of authentication is to validate the user's identity. The user's capabilities are validated through the process of obtaining authorization. The authorization tools that come pre-installed with SQL Server give users the ability to not only issue permissions but also withdraw them and refuse them. Through the use of these capabilities, users are able to establish security priorities according to their jobs and restrict data access to particular data pieces. The encryption capabilities of SQL Server make it feasible for users to keep confidential information in a secure manner. There is the capability of encrypting both files and sources, and the process of encryption can be carried out with the use of a password, symmetric key, asymmetric key, or a certificate.
The capabilities and services offered by Microsoft SQL Server 2022-
A new edition of SQL Server, known as SQL Server 2022 (16.x). The data virtualization feature is a noteworthy new addition to SQL Server. This feature gives users the ability to query different kinds of data on multiple kinds of data sources using SQL Server. The SQL Server Analysis Services that Microsoft offers have also been enhanced in the version 2022 of SQL Server. The following amendments are included in these updates:
Improvements made to the encryption method for the schema writeoperation. In order to reduce the amount of data source queries that are necessary to produce results, the Horizontal Fusion query execution plan is optimized. Both the analysis of Data Analysis Expressions queries against a DirectQuery data source and the parallel execution of independent storage engine operations against the data source are things that are planned to be executed in parallel.
Power BI models that have DirectQuery connections to Analysis Services models are now supported by SQL Server 2022 along with other models. A number of additional new features that were included in SQL Server 2022 include the following list:
Azure Synapse Link for SQL allows for analytics to be performed in a near-real-time manner over operational data. Integration of object storage within the data platform itself. The Always On and Distributed availability groups are the two types of availability groups. For improved protection of SQL servers, integration with Microsoft Defender for Cloud Apps is required. By utilizing Microsoft Entra authentication, a secure connection may be established to SQL Server. Support for the notion of least privilege with the implementation of granular access control permissions and built-in server roles. Support for system page latch concurrency, Buffer Pool Parallel Scan, enhanced columnstore segment elimination, thread management, and reduced buffer pool I/O promotions are some of the updates that have been implemented to facilitate performance enhancements.
Improvements in the performance of existing workloads can be achieved through the implementation of intelligent query processing features. Azure extensions that simplify management, server memory calculations and recommendations, snapshot backup support, Extensible Markup Language compression, and asynchronous auto update statistics concurrency are some of the features and capabilities that are included.
Additionally, SQL Server 2022 gives users access to a wide variety of tools, including the following and others:
Azure Data Studio is a tool.
The SQL Server Management Studio application.
The SQL Package.
Code written in Visual Studio.
In order for users to successfully install these features and tools, they are required to utilize the Feature Selection page of the SQL Server Installation Wizard throughout the process of installing SQL Server.
Conclusion-
SQL Server comes with a number of data management, business intelligence, and analytics solutions that are bundled together by Microsoft. SQL Server Analysis Services is an analytical engine that processes data for use in business intelligence and data visualization applications. SQL Server Reporting Services is a service that supports the creation and delivery of business intelligence reports. Also included in the data analysis offerings are R Services and Machine Learning Services, both of which were introduced for the first time in SQL Server 2016.
SQL Server Integration Services, SQL Server Data Quality Services, and SQL Server Master Data Services are all components of Microsoft SQL Server that are devoted to the handling of data. In addition, the database management system (DBMS) comes with two sets of tools for database administrators (DBAs) and developers. These tools are SQL Server Data Tools, which are used for designing databases, and SQL Server Management Studio, which is used for deploying, monitoring, and managing databases.

Janet Watson
MyResellerHome MyResellerhome.com We offer experienced web hosting services that are customized to your specific requirements. Facebook Twitter YouTube Instagram
0 notes
Text
Relational database management systems
Relational database management systems (RDBMS) have been the dominant database technology since the 1970s due to standardized structure, flexibility, integrity controls, and widespread skillsets. The tabular data model and SQL interfacing provide precision and accuracy in how data is stored, updated, retrieved and managed by multiple concurrent users.
An RDBMS stores data in linked tables with rows representing records and columns representing attributes. Structural integrity is maintained through primary keys uniquely identifying rows and foreign keys linking related data across tables. Additional validation rules can enforce data accuracy checks.
Key advantages like ACID compliance for transaction processing and flexible scaling to enterprise-levels have made RDBMS suitable for small scale applications right through to huge multi-terabyte databases. Industry standards facilitate migrating applications across platforms and minimize technology lock-ins.
In comparison, non-relational DBMS provide greater flexibility in data types and structures but lack the quality control mechanisms, transaction support and other advanced features seen in RDBMS. While the constraints add overhead, they result in far superior data quality and consistency.
Internally an RDBMS incorporates both software components like the database engine, data manipulation interfaces as well as underlying infrastructure resources like storage media and hardware servers. These components interact seamlessly to handle storage, memory, access control and backup needs automatically even in complex deployments.
The database engine is the core software component tasked with low level activities like parsing and executing SQL statements, memory allocation, file storage, disk I/O, user authentication and managing data buffers for optimal throughput. Upper layers provide the end-user tools and application connectivity layers.
Based on various design, performance and capability differences, popular relational database platforms can be categorized as enterprise-grade commercial tools like Oracle, desktop solutions like Access or high performance configurations like Exadata. RDBMS delivered over cloud infrastructure provide greater flexibility and scalability too.
A key strength responsible for the success of the technology is skill availability. Being based on open standards and decades of dominance in the industry means ample technical skills related to database administration, data modeling, report building, analytics and application development.
For the foreseeable future, RDBMS looks set to continue as the primary database technology supporting critical functions across industries and verticals. New innovations in hardware and software capabilities help continually enhance what is already a mature, trusted and versatile technology platform. With powerful inbuilt automation, integrity enforcement and flexible scalability, relational databases reduce administration overheads while supporting superior data quality and reliability leading to better
0 notes
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
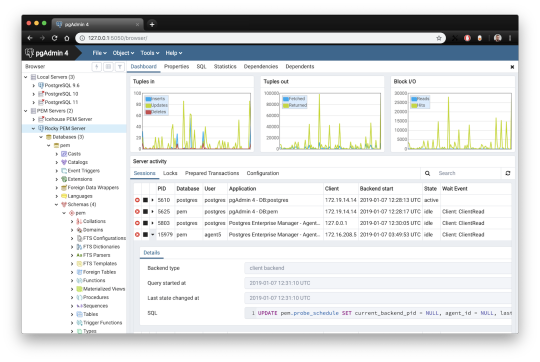
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
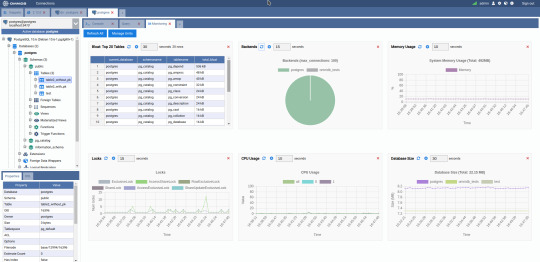
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
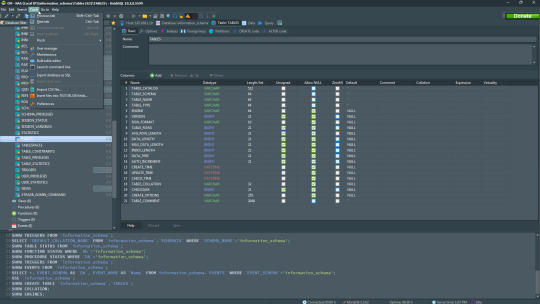
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
[ad_1] Superbass a complete back end for web and mobile applications based entirely on free open source software the biggest challenge when building an app is not writing code but rather architecting a complete system that works at scale products like Firebase and amplify have addressed this barrier but there's one Big problem they lock you into proprietary technology on a specific Cloud platform Superbass was created in 2019 specifically as an open source Firebase alternative at a high level it provides two things on the back end we have infrastructure like a database file storage and Edge functions that run in The cloud on the front end we have client-side sdks that can easily connect this infrastructure to your favorite front-end JavaScript framework react native flutter and many other platforms as a developer you can manage your postgres database with an easy to understand UI which automatically generates rest and graphql apis to use In your code the database integrates directly with user authentication making it almost trivial to implement row level security and like fire base it can listen to data changes in real time while scaling to virtually any workload to get started you can self-host with Docker or sign up for a fully managed Account that starts with a free tier on the dashboard you can create tables in your postgres database with a click of a button insert columns to build out your schema then add new rows to populate it with data by default every project has an authentication schema to manage users Within the application this opens the door to row level security where you write policies to control who has access to your data in addition the database supports triggers to react to changes in your data and postgres functions to run stored procedures directly on the database server it's a nice interface But it also automatically generates custom API documentation for you from here we can copy queries tailored to our database and use them in a JavaScript project install the Super Bass SDK with npm then connect to your project and sign a user in with a single line of Code and now we can listen to any changes to the authentication state in real time with on off stage change when it comes to the database we don't need to write raw SQL code instead we can paste in that JavaScript code from the API docs or use the rest and graphql Apis directly and that's all it takes to build an authenticated full stack application however you may still want to run your own custom server-side code in which case serverless Edge functions can be developed with Dino and typescript then easily distributed around the globe this has been super Bass in 100 seconds if you want to build something awesome on this platform we just released a brand new Super Bass course on fireship i o it's free to get started so check it out to learn more thanks for watching and I will see you in the next one [ad_2] #Supabase #Seconds For More Interesting Article Visit : https://mycyberbase.com/
0 notes
Text
Download Mysql 5.6 For Mac

Latest Version:
Requirements:
Google free download - Google Chrome, Google Workspace, Google Earth Pro, and many more programs. Download Google Chrome for Mac & read reviews. The world's number 1 browser. Google Classroom is a free collaboration tool for students and teachers. Available for download on macOS, the app lets teachers create virtual classrooms, hand out assignments, and monitor the progress of all their students. Anyone with a Google account can join and make the best use of this free and ad-free. https://foxbrands317.tumblr.com/post/654336685639974912/google-for-mac-free-download. Download Google Earth for Mac & read reviews. Take a look at the world from the eye of a satellite. Get more done with the new Google Chrome. A more simple, secure, and faster web browser than ever, with Google’s smarts built-in.
Mac OS X 10.7 or later
Author / Product: How to download gopro to mac.
Epic browser download for mac. Oracle / MySQL for Mac
Old Versions:
Filename:
mysql-5.6.16-osx10.7-x86_64.dmg
MD5 Checksum:
34814727d85ce5292ebdf1905c772d84

Mysql 5.5 Free Download
MySQL for Mac is designed for enterprise organizations delivering business critical database applications. It gives corporate developers, DBAs and ISVs an array of new enterprise features to make more productive developing, deploying, and managing industrial strength applications. If you need a GUI for MySQL Database, you can download - NAVICAT (MySQL GUI). It supports to import Oracle, MS SQL, MS Access, Excel, CSV, XML, or other formats to the tool. MySQL Database Server delivers new enterprise features, including: ACID Transactions to build reliable and secure business critical applications. Stored procedures to improve developer productivity. Triggers to enforce complex business rules at the database level. Views to ensure sensitive information is not compromised. Information schema to provide easy access to metadata. Distributed transactions (XA) to support complex transactions across multiple databases. Top 10 Reasons to Use MySQL for macOS: Scalability and Flexibility The app database server provides the ultimate in scalability, sporting the capacity to handle deeply embedded applications with a footprint of only 1MB to running massive data warehouses holding terabytes of information. High Performance A unique storage-engine architecture allows database professionals to configure the app database server specifically for particular applications, with the end result being amazing performance results. High Availability Rock-solid reliability and constant availability are hallmarks of the app, with customers relying on the program to guarantee around-the-clock uptime. Robust Transactional Support The tool offers one of the most powerful transactional database engines on the market. Features include complete ACID (atomic, consistent, isolated, durable) transaction support, unlimited row-level locking and more. Web and Data Warehouse Strengths The app is the de-facto standard for high-traffic web sites because of its high-performance query engine, tremendously fast data insert capability, and strong support for specialized web functions like fast full text searches. Strong Data Protection Because guarding the data assets of corporations is the number one job of database professionals, MySQL for Mac offers exceptional security features that ensure absolute data protection. Comprehensive Application Development One of the reasons the software is the world's most popular open source database is that it provides comprehensive support for every application development need. Within the database, support can be found for stored procedures, triggers, functions, views, cursors, ANSI-standard SQL, and more. Management Ease The program offers exceptional quick-start capability with the average time from software download to installation completion being less than fifteen minutes. Open Source Freedom and 24 x 7 Support Many corporations are hesitant to fully commit to open source software because they believe they can't get the type of support or professional service safety nets they currently rely on with proprietary software to ensure the overall success of their key applications. Lowest Total Cost of Ownership By migrating current database-drive applications to the app, or using the tool for new development projects, corporations are realizing cost savings that many times stretch into seven figures. Also Available: Download MySQL for Windows
Mysql 5.6.2
For example, the MySQL Client that comes with this package matches MySQL 4.1.14, so if you have MySQL 5.0.18 installed, then some functions may/will fail. It may not make much difference to the average user, but just know that it is best (and recommended by mysql.com) that your mysql client api is at least current with whatever server version. MySQL Cluster CGE. MySQL Cluster is a real-time open source transactional database designed for fast, always-on access to data under high throughput conditions. MySQL Cluster; MySQL Cluster Manager; Plus, everything in MySQL Enterprise Edition; Learn More » Customer Download » (Select Patches & Updates Tab, Product Search) Trial Download ».
0 notes
Text
8 Benefits Of Using MySQL

MySQL is an open-source RDBMS or relational database management system. Data is created, modified, and extracted from the relational database by programmers using SQL or structured query language. And data, including data types related to each other, are organized into data tables by a relational database. Though MySQL is mostly used with other programs, it has stand-alone clients as well. Moreover, many popular websites, as well as database-driven web applications, use MySQL. Here are the 8 benefits of MySQL installation and using MySQL.
Data Security
The first and foremost thing considered in any database management system is data security, and MySQL is one of the most secure database management systems. Besides, securing data is of utmost importance since your business could even get compromised without data security. What's more, MySQL is used by popular web applications like Drupal, Joomla, WordPress and popular websites like Facebook and Twitter. Further, it has security features to prevent unauthorized access to sensitive data and is suitable for businesses, especially those requiring frequent money transfers.
Scalability
MySQL also offers on-demand scalability, which can be beneficial with the growth of data and technology. So you can scale up or scale down your requirements as and when required. Thus, it facilitates the management of applications no matter the amount of data. For instance, it enables you to handle spreading databases, varying loads of application queries, etc with ease.
High Performance
The storage engine framework used in MySQL allows system managers to set up database servers that are high performing yet flawless. Hence, it can handle a large number of queries your business may receive and still ensure optimal speed. Database indexes, replication, clustering helps boost performance while managing heavy loads.
24x7 Uptime
Being available round the clock is significant for a business to generate revenue. However, MySQL ensures 24x7 uptime with its clustering and replication configurations. When a failure occurs, the cluster servers manage it and keep the system running. And if one server fails, the user will be redirected to another one to complete the query.
Transactional Support
MySQL provides all-inclusive transactional support with several transaction support features. It includes row-level locking, database transactions with ACID or atomicity, consistency, isolation, and durability, multi-version transaction support, and so on. After all, if you are looking for data integrity, MySQL gives that as well.
Workflow Control
Furthermore, MySQL comes with cross-platform capabilities, and the time required to download and install it is relatively low. Therefore, it can be used right away once the installation is complete, whether the system platform is Windows, Linux, macOS, or others. Also, everything is automated with its self-management features. Ultimately, it lets you keep complete workflow control.
Reduced Total Cost
MySQL offers reliability and is easily manageable with so many features. As a result, time and money used for troubleshooting, fixing downtimes or performance issues are saved, thus reducing the total cost involved.
Flexibility
MySQL makes debugging, upgrading, and maintenance effortless as well as enhances the end-user experience. Besides, it lets you customize configurations your way, making it a flexible open-source database management system.
#mysql server#mysql server service#manjaro mysql installation#mysql dats base#mysql service in calicut#mysql server service in kerala#web hosting support service#24x7 technical support company#hosting support services#Cloud Management Services
0 notes
Text
Oimerp Driver Download


Oimerp Driver Download Pc

Oimerp Driver Download Torrent
In reply to Omer Coskun's post on August 25, 2010 I installed it and can see it in add/remove programs but devive manager still has a yellow question mark. I tried to reintall driver tab but got a message one cound not be found. Omer Faruk free download - Omer Reminder, OMeR X, Omer Counter, and many more programs. Download Chrome For Windows 10/8.1/8/7 32-bit. For Windows 10/8.1/8/7 64-bit. This computer will no longer receive Google Chrome updates because Windows XP and Windows Vista are no longer. View & download of more than 498 Cerwin-Vega PDF user manuals, service manuals, operating guides. Speakers, Subwoofer user manuals, operating guides & specifications.
Aarp Safe Driver
Object TypeActionsViewersCatalogs
Create Database Catalogs CatalogReferences, Tables SchemasCreate Schema Schemas SchemaExport Schema, Drop Schema References, Tables TablesCreate Table, Import Table DataReferences, Tables TableAlter Table, Create Trigger, Export Table, Import Table Data, Add Extended Property, Create Index, Delete Extended Property, Drop Table, Edit Extended Property, Empty Table, Rename Table, Script: Script Table Navigator1, References, Data, Columns, DDL, Extended Properties, Grants, Indexes, Indexes2, Info, Primary Key, Row Count, Row Id, Triggers HistoryTable3 Extended Properties, Grants, Indexes, Info Columns Columns, Extended Properties ColumnAdd Extended Property, Delete Extended Property, Edit Extended Property, Rename Column Column, Extended Properties Indexes Indexes IndexDrop Index, Rebuild Index4, Rename Index DDL4, Index Triggers Triggers TriggerExport Trigger, Disable Trigger, Drop Trigger, Enable Trigger, Rename Trigger Trigger Editor, Info Views Views ViewExport View, Add Extended Property, Create Trigger, Delete Extended Property, Drop View, Edit Extended Property, Rename View, Script: Script View Data, Columns, DDL, Extended Properties, Indexes, Info, Row Count Columns Columns, Extended Properties ColumnAdd Extended Property, Delete Extended Property, Edit Extended Property, Rename Column Column, Extended Properties Triggers Triggers TriggerExport Trigger, Disable Trigger, Drop Trigger, Enable Trigger, Rename Trigger Trigger Editor, Info SynonymsCreate Synonym Synonyms SynonymDrop Synonym Info Indexes Indexes IndexDrop Index, Rebuild Index4, Rename Index DDL4, Index Sequences5Create Sequence Sequences SequenceDrop Sequence Info Types User Defined Data Types Triggers Triggers TriggerExport Trigger, Disable Trigger, Drop Trigger, Enable Trigger, Rename Trigger Trigger Editor, Info ProceduresCreate Procedure Procedures ProcedureExport Procedure, Drop Procedure, Rename Procedure, Script: Script Procedure Procedure Editor, Interface FunctionsCreate Function Functions FunctionExport Function, Drop Function, Rename Function, Script: Script Function Function Editor, Interface Users6 Users Roles Roles Role Info, Users6LinkedServers7Create Linked Server1 Linked Servers LinkedServerAdd Login, Drop Linked Server Login, Drop Linked Server1, Enable/Disable Options, Set Remote Collation, Set Timeout Options, Test Connection1 Info LinkedServerCatalogs Catalogs LinkedServerCatalogLinkedServerSchemas Schemas LinkedServerSchemaLinkedServerTables Tables LinkedServerTableData, Columns, Foreign Keys, Grants, Info, Primary Key, Row Count LinkedServerColumns Columns LinkedServerColumn Column LinkedServerViews Views LinkedServerViewData, Columns, Info, Row Count LinkedServerColumns Columns LinkedServerColumn Column LinkedServerSynonyms Synonyms LinkedServerSynonym Column DBA DBA ServerInfo Latest Error Log6, Server Info Logins6 Logins Devices6 Database Devices Processes6 Processes ServerRoles6 Roles ServerRole Info, Users ServerAgent8 Latest Error Log, Sql Server Agent JobsCreate Job Jobs JobCreate Step, Delete Job, Edit, Edit Notifications, Enable/Disable Job, Start the job Alerts, History, Steps, info JobStepCopy Step, Delete Job Step, Edit Step info JobSchedulesAttach Schedule Schedules JobScheduleDetach Schedule, Enable/Disable Schedule Schedules JobServersAdd Server Servers JobServerDelete Server Server SchedulerSchedulesAdd Recurring Daily, Add Recurring Monthly, Add Recurring Weekly, Add one time, Add other Schedules SchedulerScheduleDelete Schedule, Enable/Disable Schedule Jobs, Schedules Alerts Alerts Alert Alert, Operators Operators Operators Operator Alerts, Info, Jobs Locks6 Locks 1)DbVisualizer Pro 2)Version 10 and later 3)Version 13 and later 4)Version 9 and later 5)Version 11 and later 6)Not Azure SQL Database 7)Version 10 and when linked servers is supported 8)Version 9 and not Azure SQL Database
0 notes
Text
10 Effective Strategies to Prevent and Resolve SQL Server Deadlocks
Understanding Deadlocks A deadlock occurs when two or more processes hold locks on resources the others need, with each process waiting for the other to release its lock. This creates a cycle of dependencies that SQL Server resolves by terminating one process, allowing the others to continue. Dealing with deadlocks in SQL Server, especially when your procedures involve adding records and then…
View On WordPress
#deadlock graphs analysis#deadlock resolution strategies#row-level locking#SQL Server deadlocks#transaction optimization
0 notes
Text
MySQL Monitoring and Reporting Using the MySQL Shell
MySQL Shell is the advanced MySQL client, which has many excellent features. In this blog, I am going to explain the MySQL shell commands “show” and “watch”. Both commands are very useful to monitor the MySQL process. It provides more insights into the foreground and background threads as well. Overview “show” and “watch” are the MySQL shell commands, which can be executed using the Javascript (JS), Python (Py), and SQL interfaces. Both commands are providing the same information, but the difference is you can refresh the results when using the command “watch”. The refresh interval is two seconds. show: Run the specified report using the provided options and arguments. watch: Run the specified report using the provided options and arguments, and refresh the results at regular intervals. Below are the available options you can use with the “show” or “watch” command to retrieve the data.MySQL localhost:33060+ ssl percona JS > show Available reports: query, thread, threads. MySQL localhost:33060+ ssl percona JS > watch Available reports: query, thread, threads. Query Thread Threads “show” with “query” It will just execute the query provided as an argument within the double quotes and print the result. MySQL localhost:33060+ ssl percona JS > show query "select database()" +------------+ | database() | +------------+ | percona | +------------+ MySQL localhost:33060+ ssl percona JS > show query --vertical "select database()" *************************** 1. row *************************** database(): perconaYou can also use the same option with the “watch” command. Let’s say, if you want to monitor the processlist for every two seconds, then you can use the command likewatch query “show processlist” Have open source expertise you want to share? Submit your talk for Percona Live ONLINE 2021! “show” with “thread” This option is designed to provide various information about the specific thread. Below are some of the important details you can retrieve from the specific thread. InnoDB details ( –innodb ) Locks Details ( –locks ) Prepared statement details ( –prep-stmts ) Client connection details ( –client ) Session status ( –status ) and session variables details ( –vars ) Example: I am going to show the example for the below scenario. At session1: My connection id is 121. I have started the transaction and updated the row where “id=3”. But, still not committed or rolled back the transaction.mysql> r Connection id: 121 Current database: percona mysql> select * from herc; +------+--------+ | id | name | +------+--------+ | 1 | jc | | 2 | herc7 | | 3 | sakthi | +------+--------+ 3 rows in set (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update herc set name='xxx' where id=3; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0At session 2: My connection id is 123. I have started the transaction and tried to update the same row where “id=3”. The query is still executing because the transaction from session 1 is blocking the row ( id = 3 )mysql> r Connection id: 123 Current database: percona mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update herc set name='hercules' where id=3;Now let’s use the command “show thread” for both connection IDs (121, 123) and see what information we can get. General information ( conncetion id = 123 ):MySQL localhost:33060+ ssl JS > show thread --cid=123 --general GENERAL Thread ID: 161 Connection ID: 123 Thread type: FOREGROUND Program name: mysql User: root Host: localhost Database: percona Command: Query Time: 00:08:49 State: updating Transaction state: LOCK WAIT Prepared statements: 0 Bytes received: 282 Bytes sent: 131 Info: update herc set name='hercules' where id=3 Previous statement: NULLFrom the general information, you can find some basic information about your id. InnoDB information:MySQL localhost:33060+ ssl JS > show thread --cid=123 --innodb INNODB STATUS State: LOCK WAIT ID: 28139179 Elapsed: 00:10:23 Started: 2021-02-23 17:40:06.000000 Isolation level: REPEATABLE READ Access: READ WRITE Locked tables: 1 Locked rows: 1 Modified rows: 0Using the “–innodb” option, you can find out the information about the InnoDB like transaction state, thread start time, elapsed time, locked tables, rows, modified rows. Locks information: For connection id 123:MySQL localhost:33060+ ssl JS > show thread --cid=123 --locks LOCKS Waiting for InnoDB locks +---------------------+----------+------------------+--------+-----+-------+----------------+---------------------+----------+ | Wait started | Elapsed | Locked table | Type | CID | Query | Account | Transaction started | Elapsed | +---------------------+----------+------------------+--------+-----+-------+----------------+---------------------+----------+ | 2021-02-23 17:40:06 | 00:12:27 | `percona`.`herc` | RECORD | 121 | NULL | root@localhost | 2021-02-23 17:39:32 | 00:13:01 | +---------------------+----------+------------------+--------+-----+-------+----------------+---------------------+----------+ Waiting for metadata locks N/A Blocking InnoDB locks N/A Blocking metadata locks N/AConnection id 123 is from session 2. Which is currently waiting to release the lock from connection id 121 (session 1). Let’s see the “–locks” status for connection id 121.MySQL localhost:33060+ ssl JS > show thread --cid=121 --locks LOCKS Waiting for InnoDB locks N/A Waiting for metadata locks N/A Blocking InnoDB locks +---------------------+----------+------------------+--------+-----+--------------------------------------------+ | Wait started | Elapsed | Locked table | Type | CID | Query | +---------------------+----------+------------------+--------+-----+--------------------------------------------+ | 2021-02-23 17:40:06 | 00:14:23 | `percona`.`herc` | RECORD | 123 | update herc set name='hercules' where id=3 | +---------------------+----------+------------------+--------+-----+--------------------------------------------+ Blocking metadata locks N/AHere, you can find the details on “Blocking InnoDB Locks”. It blocks the connection id 123 (session 2). Like the above example, you can explore the other options as well, which are helpful. “show” with “threads” This is very helpful to know the details about your ongoing threads. It will provide the details about both “FOREGROUND” and “BACKGROUND” threads. There are many columns, which are very useful to know about thread status. You can filter the needed columns with the option “-o”. By executing the command “show threads –help”, you can find all the available options and their purposes. It supports the WHERE clause for generating the report It supports ORDER BY for generating the report It supports LIMIT for generating the report. Below, I am sharing some examples, which will help you to understand how we can use the “threads” command with the MySQL shell. How to find the running “FOREGROUND” threads details How to find the running “BACKGROUND” threads details How to find the top five threads, which are consuming more memory from a particular user How to find the Query digest details from ongoing threads How to find the top five threads which consumed huge IO operations How to find the top five blocked and blocking threads I am running the sysbench against the server to get my database loaded. sysbench /usr/share/sysbench/oltp_read_write.lua --events=0 --time=30000 --mysql-host=localhost --mysql-user=root --mysql-password=Course@321 --mysql-port=3306 --delete_inserts=10 --index_updates=10 --non_index_updates=10 --report-interval=1 --threads=100 run How to Find the Running “FOREGROUND” Threads Details You can use the option “–foreground” to see all the running foreground threads.MySQL localhost:33060+ ssl JS > show threads --foreground +-----+-----+-----------------+-----------+---------+---------+----------+------------------------+-----------+-------------------------------------------------------------------+-----------+ | tid | cid | user | host | db | command | time | state | txstate | info | nblocking | +-----+-----+-----------------+-----------+---------+---------+----------+------------------------+-----------+-------------------------------------------------------------------+-----------+ | 27 | 114 | root | localhost | NULL | Query | 00:00:00 | executing | NULL | SELECT json_object('cid',t.PRO ... READ_ID = io.thread_id WHERE t | 0 | | 42 | 5 | event_scheduler | localhost | NULL | Daemon | 17:42:20 | Waiting on empty queue | NULL | NULL | 0 | | 46 | 7 | NULL | NULL | NULL | Daemon | 17:42:20 | Suspending | NULL | NULL | 0 | | 158 | 120 | root | localhost | NULL | Sleep | 00:32:24 | NULL | NULL | . . . . .. . ... . . . .. . .. . .. . . . . . .. . ... . . . .. . .. . .. . . . . . .. . ... . . . .. . .. . .. . | 0 | | 260 | 222 | root | localhost | sbtest | Execute | 00:00:00 | updating | LOCK WAIT | NULL | 1 | | 261 | 223 | root | localhost | sbtest | Execute | 00:00:00 | updating | LOCK WAIT | NULL | 0 | +-----+-----+-----------------+-----------+---------+---------+----------+------------------------+-----------+-------------------------------------------------------------------+-----------+ How to Find the Running “BACKGROUND” Threads Details This will give detailed information about the background threads, mostly InnoDB. You can use the flag “–background” to get these details. These details will be really helpful for debugging the performance issues.MySQL localhost:33060+ ssl JS > show threads --background +-----+--------------------------------------+---------+-----------+------------+------------+------------+ | tid | name | nio | ioltncy | iominltncy | ioavgltncy | iomaxltncy | +-----+--------------------------------------+---------+-----------+------------+------------+------------+ | 1 | sql/main | 92333 | 192.51 ms | 229.63 ns | 96.68 us | 1.42 ms | | 3 | innodb/io_ibuf_thread | NULL | NULL | NULL | NULL | NULL | | 4 | innodb/io_log_thread | NULL | NULL | NULL | NULL | NULL | | 5 | innodb/io_read_thread | NULL | NULL | NULL | NULL | NULL | | 6 | innodb/io_read_thread | NULL | NULL | NULL | NULL | NULL | | 7 | innodb/io_read_thread | NULL | NULL | NULL | NULL | NULL | | 8 | innodb/io_read_thread | NULL | NULL | NULL | NULL | NULL | | 9 | innodb/io_write_thread | 37767 | 45.83 s | 1.26 us | 1.21 ms | 17.81 ms | | 10 | innodb/io_write_thread | 36763 | 44.57 s | 1.23 us | 1.21 ms | 30.11 ms | | 11 | innodb/io_write_thread | 37989 | 45.87 s | 1.26 us | 1.21 ms | 24.03 ms | | 12 | innodb/io_write_thread | 37745 | 45.78 s | 1.23 us | 1.21 ms | 28.93 ms | | 13 | innodb/page_flush_coordinator_thread | 456128 | 2.19 min | 5.27 us | 419.75 us | 29.98 ms | | 14 | innodb/log_checkpointer_thread | 818 | 479.84 ms | 2.62 us | 710.63 us | 9.26 ms | | 15 | innodb/log_flush_notifier_thread | NULL | NULL | NULL | NULL | NULL | | 16 | innodb/log_flusher_thread | 1739344 | 41.71 min | 1.46 us | 1.44 ms | 30.22 ms | | 17 | innodb/log_write_notifier_thread | NULL | NULL | NULL | NULL | NULL | | 18 | innodb/log_writer_thread | 5239157 | 10.23 min | 1.14 us | 117.16 us | 29.02 ms | | 19 | innodb/srv_lock_timeout_thread | NULL | NULL | NULL | NULL | NULL | | 20 | innodb/srv_error_monitor_thread | NULL | NULL | NULL | NULL | NULL | | 21 | innodb/srv_monitor_thread | NULL | NULL | NULL | NULL | NULL | | 22 | innodb/buf_resize_thread | NULL | NULL | NULL | NULL | NULL | | 23 | innodb/srv_master_thread | 270 | 4.02 ms | 6.75 us | 14.90 us | 41.74 us | | 24 | innodb/dict_stats_thread | 3088 | 429.12 ms | 3.22 us | 138.96 us | 5.93 ms | | 25 | innodb/fts_optimize_thread | NULL | NULL | NULL | NULL | NULL | | 26 | mysqlx/worker | NULL | NULL | NULL | NULL | NULL | | 28 | mysqlx/acceptor_network | NULL | NULL | NULL | NULL | NULL | | 32 | innodb/buf_dump_thread | 1060 | 7.61 ms | 2.74 us | 7.18 us | 647.18 us | | 33 | innodb/clone_gtid_thread | 4 | 689.86 us | 4.46 us | 172.46 us | 667.95 us | | 34 | innodb/srv_purge_thread | 7668 | 58.21 ms | 3.34 us | 336.20 us | 1.64 ms | | 35 | innodb/srv_worker_thread | 30 | 278.22 us | 5.57 us | 9.27 us | 29.69 us | | 36 | innodb/srv_purge_thread | NULL | NULL | NULL | NULL | NULL | | 37 | innodb/srv_worker_thread | NULL | NULL | NULL | NULL | NULL | | 38 | innodb/srv_worker_thread | 24 | 886.23 us | 5.24 us | 36.93 us | 644.75 us | | 39 | innodb/srv_worker_thread | NULL | NULL | NULL | NULL | NULL | | 40 | innodb/srv_worker_thread | 22 | 223.92 us | 5.84 us | 10.18 us | 18.34 us | | 41 | innodb/srv_worker_thread | NULL | NULL | NULL | NULL | NULL | | 43 | sql/signal_handler | NULL | NULL | NULL | NULL | NULL | | 44 | mysqlx/acceptor_network | NULL | NULL | NULL | NULL | NULL | +-----+--------------------------------------+---------+-----------+------------+------------+------------+ How to Find the Top Five Threads, Which are Consuming More Memory From a Particular User From the below example, I am finding the top five threads, which are consuming more memory from user “root”. MySQL localhost:33060+ ssl JS > show threads --foreground -o tid,user,memory,started --order-by=memory --desc --where "user = 'root'" --limit=5 +-----+------+----------+---------------------+ | tid | user | memory | started | +-----+------+----------+---------------------+ | 247 | root | 9.47 MiB | 2021-02-23 18:30:29 | | 166 | root | 9.42 MiB | 2021-02-23 18:30:29 | | 248 | root | 9.41 MiB | 2021-02-23 18:30:29 | | 186 | root | 9.39 MiB | 2021-02-23 18:30:29 | | 171 | root | 9.38 MiB | 2021-02-23 18:30:29 | +-----+------+----------+---------------------+ How to Find the Query Digest Details From Ongoing Threads You can use the options “digest” and “digesttxt” to find the digest output of the running threads.MySQL localhost:33060+ ssl JS > show threads -o tid,cid,info,digest,digesttxt --where "digesttxt like 'UPDATE%'" --vertical *************************** 1. row *************************** tid: 161 cid: 123 info: update herc set name='hercules' where id=3 digest: 7832494e46eee2b28a46dc1fdae2e1b18d1e5c00d42f56b5424e5716d069fd39 digesttxt: UPDATE `herc` SET NAME = ? WHERE `id` = ? How to Find the Top Five Threads Which Consumed Huge IO Operations MySQL localhost:33060+ ssl JS > show threads -o tid,cid,nio --order-by=nio --desc --limit=5 +-----+-----+-------+ | tid | cid | nio | +-----+-----+-------+ | 27 | 114 | 36982 | | 238 | 200 | 2857 | | 215 | 177 | 2733 | | 207 | 169 | 2729 | | 232 | 194 | 2724 | +-----+-----+-------+Nio → Total number of IO events for the thread. How to Find the Top Five Blocked and Blocking Threads nblocked – The number of other threads blocked by the thread nblocking – The number of other threads blocking the thread Ntxrlckd – The approximate number of rows locked by the current InnoDB transaction Blocking threads:MySQL localhost:33060+ ssl JS > show threads -o tid,cid,nblocked,nblocking,ntxrlckd,txstate --order-by=nblocking --desc --limit 5 +-----+-----+----------+-----------+----------+-----------+ | tid | cid | nblocked | nblocking | ntxrlckd | txstate | +-----+-----+----------+-----------+----------+-----------+ | 230 | 192 | 0 | 7 | 5 | LOCK WAIT | | 165 | 127 | 0 | 6 | 2 | LOCK WAIT | | 215 | 177 | 0 | 5 | 9 | LOCK WAIT | | 221 | 183 | 0 | 4 | NULL | NULL | | 233 | 195 | 1 | 4 | NULL | NULL | +-----+-----+----------+-----------+----------+-----------+Blocked threads:MySQL localhost:33060+ ssl JS > show threads -o tid,cid,nblocked,nblocking,ntxrlckd,txstate --order-by=nblocked --desc --limit 5 +-----+-----+----------+-----------+----------+-----------+ | tid | cid | nblocked | nblocking | ntxrlckd | txstate | +-----+-----+----------+-----------+----------+-----------+ | 203 | 165 | 15 | 0 | 8 | LOCK WAIT | | 181 | 143 | 10 | 1 | 5 | LOCK WAIT | | 223 | 185 | 9 | 0 | 8 | LOCK WAIT | | 209 | 171 | 9 | 1 | 5 | LOCK WAIT | | 178 | 140 | 6 | 0 | 7 | LOCK WAIT | +-----+-----+----------+-----------+----------+-----------+Like this, you have many options to explore and you can generate the report based on your requirements. I hope this blog post is helpful to understand the “show” and “watch” commands from the MySQL shell! https://www.percona.com/blog/2021/02/25/mysql-monitoring-and-reporting-using-the-mysql-shell/
0 notes
Text
T SQL Advanced Tutorial By Sagar Jaybhay 2020
New Post has been published on https://is.gd/AQSl2U
T SQL Advanced Tutorial By Sagar Jaybhay 2020
In this article we will understand T SQL Advanced Tutorial means Transaction In SQL and Common Concurrency Problem and SQL server transaction Isolation level by Sagar Jaybhay
What is the Transaction?
A transaction is a group of commands that changed the data stored in a database. A transaction is treated as a single unit.
The transaction ensures that either all commands will succeed or none of them. Means anyone fails then all commands are rolled back and data that might change is reverted back to the original state. A transaction maintains the integrity of data in a database.
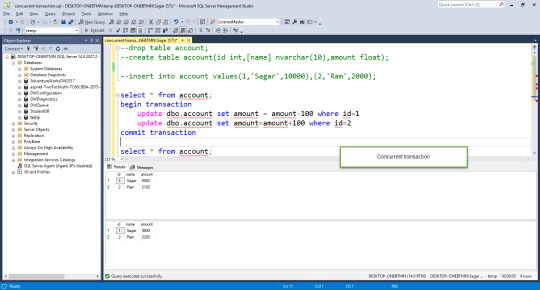
begin try begin transaction update dbo.account set amount = amount-100 where id=1 update dbo.account set amount=amount+100 where id=2 commit transaction print 'transaction committed' end try begin catch rollback transaction print 'transaction rolled-back' end catch
In the above example either both statements executed or none of them because it goes in catch block where we rolled-back transactions.
begin try begin transaction update dbo.account set amount = amount-100 where id=1 update dbo.account set amount=amount+100 where id='A' commit transaction print 'transaction commited' end try begin catch rollback transaction print 'tranaction rolledback' end catch
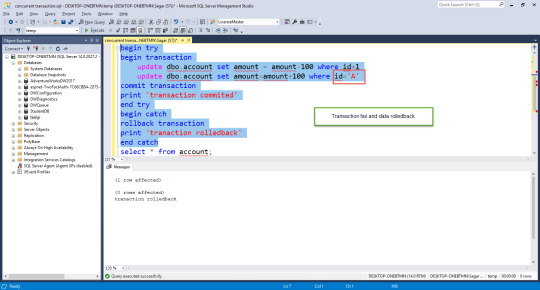
Common Concurrency Problem
Dirty reads
Lost update
Nonrepetable reads
Phantom reads
SQL server transaction Isolation level
Read Uncommitted
Read committed
Repeatable read
Snapshot
Serializable
How to overcome the concurrency issues?
One way to overcome this issue is to allow only one user at the time allowed for the transaction.
Dirty Read Concurrency Problem:
A dirty read happens when one transaction permitted to read data that modified by another transaction but that yet not committed. Most of the time it will not cause any problem because if any case transaction fails then the first transaction rolled back its data and the second transaction not have dirty data that also not exist anymore.
To do 2 transactions on one machine open 2 query editor that is your 2 transaction machine and you do an operation like below
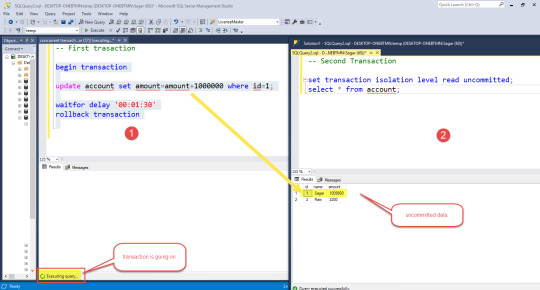
For the first transaction, we update the amount in the account table and then given a delay for 1 min 30 seconds and after this, we rollback the transaction. And in the second window, we select data from a table where we can see uncommitted data and after transaction rollback, we see committed data.
We have default isolation level read committed to set different for reading uncommitted data you can use below command.
set transaction isolation level read uncommitted; -- the First transaction begin transaction update account set amount=amount+1000000 where id=1; waitfor delay '00:01:30' rollback transaction -- Second Transaction set transaction isolation level read uncommitted; select * from account;
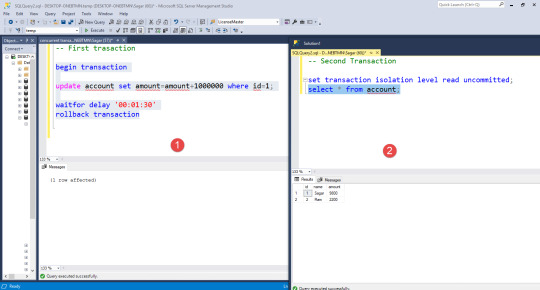
Lost Update
It means that 2 transactions read and update the same data. When one transaction silently overrides the data of another transaction modified this is called a lost update.
Both read committed and read uncommitted have lost update side effects.
Repeatable reads, snapshots, and serialization do not have these side effects.
Repeatable read has an additional locking mechanism that Is applied on a row that read by current transactions and prevents them from updated or deleted from another transaction.
-- first transaction begin transaction declare @amt float select @amt=amount from account where id =1; waitfor delay '00:01:20' set @amt=@amt-1000 update account set amount=@amt where id=1; print @amt commit transaction -- first tarnsaction -- second transaction begin transaction declare @amt float select @amt=amount from account where id =1; waitfor delay '00:00:20' set @amt=@amt-2000 update account set amount=@amt where id=1; print @amt commit transaction
Non-Repeatable read
It was when the first transaction reads the data twice and the second transaction updates the data in between the first and second transactions.
Phantom read
It happens when one transaction executes a query twice and it gets a different number of rows in the result set each time. This happens when a second transaction inserts a new record that matches where the clause of executed by the first query.
To fix phantom read problem we can use serializable and snapshot isolation levels. When we use the serializable isolation level it would apply the range lock. Means whatever range you have given in first transaction lock is applied to that range by doing so second transaction not able to insert data between this range.
Snapshot isolation level
Like a serializable isolation level snapshot also does not have any concurrency side effects.
What is the difference between serializable and Snapshot isolation level?
Serialization isolation level acquires it means during the transaction resources in our case tables acquires a lock for that current transaction. So acquiring the lock it reduces concurrency reduction.
Snapshot doesn’t acquire a lock it maintains versioning in TempDB. Since snapshot does not acquire lock resources it significantly increases the number of concurrent transactions while providing the same level of data consistency as serializable isolation does.
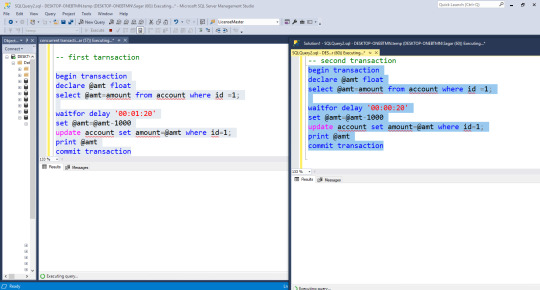
See below the image in that we use a serializable isolation level that acquires a lock so that we are able to see the execution of a query in progress.
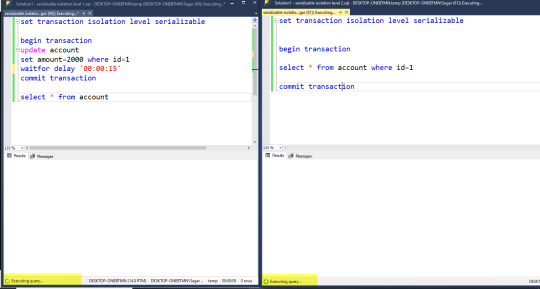
Now in the below example, we set a database for allowing snapshot isolation. For that, we need to execute the below command.
alter database temp set allow_snapshot_isolation on
Doing so our database tempdb is allowed for snapshot transaction than on one window we use serialization isolation level and on the second we use snapshot isolation level. When we run both transactions we are able to see the snapshot isolation level transaction completed while serialization is in progress and after completing both transactions we see one window has updated data and others will have previous data. First

Now after completing both transactions
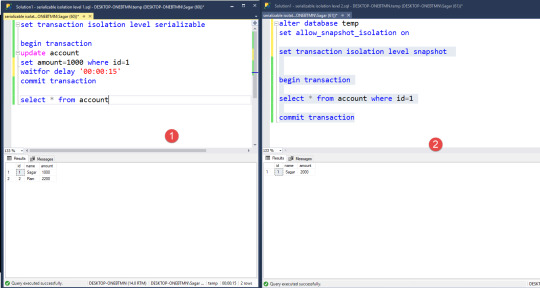
snapshot isolation never blocks the transaction.
It will display that data which is before another transaction processing
It means that snapshot isolation never locks resources and other transaction able read the data
But here one transaction is updating the data another is reading that data so it’s ok
When both transactions updating same data then transaction blocks and this blocks until the first transaction complete and then transaction 2 throws error lost update why because preventing overwriting the data and it fails and error is transaction is aborted you can’t use snapshot isolation level update, delete insert that had been deleted or modified by another transaction.
If you want to complete the second transaction you need to rerun that transaction and data is modified successfully.
Read Committed Snapshot Isolation Level
It is not a different isolation level. It is an only different way of implementing Read committed isolation level. one problem in that if anyone transaction is updating the record while reading the same data by another transaction is blocked.
Difference between Snapshot isolation level and Read Committed Snapshot isolation level.
Snapshot IsolationRead Committed Snapshot isolation levelIt is vulnerable to update conflictsNo update conflicts hereCan not use with a distributed transactionIt can work with a distributed transactionProvides transaction-level read consistencyIt provides statement-level read consistency
My Other Site: https://sagarjaybhay.net
0 notes
Text
300+ TOP Oracle Applications Interview Questions and Answers
Oracle Applications Interview Questions for freshers experienced :-
1. What are the steps in attaching reports with oracle applications? There are certain steps that you need to follow systematically for attaching the reports along with oracle application. Designing the report. Generating executable file related with report. Moving executable and source files to the appropriate folder of the product. Registering the report in the form of concurrent executable. Defining concurrent program for registered that are executable. Adding concurrent program for requesting group of responsibility. 2. Differentiate Apps schema from other schemas? Apps schema is the one that comprises of only synonyms and there is no possibility of creating tables in it. Other schema comprises of tables and objects in it and allows the creation of tables as well as for providing grants to tables. 3. Define custom top and its purpose. Custom top can be defined as the customer top which is created exclusively for customers. According to the requirement of the client many number of customer tops can be made. Custom top is made used for the purpose of storing components, which are developed as well as customized. At the time when the oracle corporation applies patches, every module other than custom top are overridden. 4. What is the method of calling standard – interface program from pl/sql or sql code? FND_REQUEST.SUBMIT_REQUEST(PO, EXECUTABLE NAME,,,,,PARAMETERS) 5. What is the significance related with US folder? US folder is just a language specification. Multiple folders can be kept for language specification depending on the languages that are installed. 6. Which are the kinds of report triggers? There are mainly five different kinds of report triggers available. They are Before report After report Before parameter form After parameter form Between pages 7. What is the firing sequence related with report triggers? The sequence related with firing is as follows before parameter form, after parameter form, before the report, between pages and after report. 8. What is the purpose of cursors in PL/SQL? The cursor can be made used for the purpose of handling various row – query associated with PL/SQL. Implicit cursors are available for the purpose of handling all the queries related with oracle. The memory spaces that are unnamed are used by oracle for storing the data that can be used with implicit cursors. 9. Define record group? Record group can be considered as a concept used for the purpose of holding sql query that is associated with list related with values. Record group consists of static data and also can access data inside tables of database through sql queries. 10. What is a FlexField? This is a kind of field associated with oracle apps that are used for capturing information related with the organization.

Oracle Applications Interview Questions 11. Is there any possibility for having custom schema at any time when it is required? You have the provision for having custom schema at the time of creating table. 12. What is the concurrent program? Concurrent programs are instances that need to be executed along with incompatibles and parameters. 13. Define application top? Application tops are found when we are connecting to server. There are two types of application tops available they are product top and custom top. Product top is the kind of top that is built in default by manufacturer. Custom top can be chosen by the client, and any number of custom tops can be created as per the requirement of the client. 14. Explain about the procedures that are compulsory in the case of procedures? There are number of parameters which are mandatory in the case of procedures and each of these parameters has a specific job associated with it. Errorbuf: This is the parameter used for returning error messages and for sending that to log file. Retcode: This is the parameter capable of showing the status associated with a procedure. 0, 1 and 2 are the status displayed by this parameter. 0 is used for indicating completed normal status, 1 defines completed warning status and 2 is the one denoting completed with error. 15. What is a token? Token is used for transferring values towards report builder. Tokens are usually not case – sensitive. 16. What is the menu? Menu can be defined as a hierarchical arrangement associated with functions of the system. 17. What is Function? Function is the smaller part of the application and that is defined inside menu. 18. Define SQL Loader ? Sql loader is a utility resembling a bulk loader for the purpose of moving data that are present in external files towards the oracle database. 19. How to register concurrent program with oracle apps? There are certain steps that you need to follow for the purpose of registering concurrent program. The first step is to log in to your system with the responsibility of the system administrator. The next step is to define executable concurrent program. While defining concurrent program do take care to give application name, short name and description along with the selection of executable concurrent program. 20. Define set – of books? SOB can be defined as the collection of charts associated with accounts, currency and calendars. 21. What is a value set? Value set is used for the purpose of containing the values. In the case of a value set getting associated with report parameters, a list containing values are sent to the user for accepting one among the values in the form of parameter values. 22. Define the Types of validation? There are various kinds of validation. None: this is the indication of minimal validation. Independent: Input should be there in the list of – values that are defined previously. Dependent: According to the previous value, input is compared with a subset of values. Table: Input is checked on the basis of values that exist in the application table. Special: These are the values that make use of flex field. Pair: A pair can be defined as the set of values that make use of flex fields. Translated Independent: This is a kind of value that can be made used only if there is any existence for the input in the list that is defined previously. Translatable dependent: In this kind of validation rules that compare the input with the subset of values associated with the previously defined list. 23. What is Template? Template is a kind of form that is very much required before the creation of any other type of forms. It is a kind of form that incorporates attachments that are platform independent and associated with a particular library. 24. Which are the attachments that are platform independent and become a part of the template? There are several attachments that are part of the template form. APPSCORE: This is a kind of attachment that comprises of packages as well as procedures which are useful for all the different forms for the purpose of creating toolbars, menus etc. APPSDAYPK: This attachment contains packages that are helpful in controlling the applications associated with oracle. FNDSQF: This attachment has various procedures as well as packages for flex fields, profiles, message dictionary and also concurrent processing. CUSTOM: This attachment is helpful in extending the application forms of oracle without causing any modification related with the application code. There are various kinds of customization including zoom. 25. Define Ad-hoc reports? This is a kind of report that is made used for fulfilling the reporting needs of a particular time. 26. What is the Definition of responsibility? Responsibility is the method through which the group of various modules can be made in a format accessible by users. 27. Define Autonomous transaction? This is a kind of transaction that is independent of another transaction. This kind of transaction allows you in suspending the main transaction and helps in performing SQL operations, rolling back of operations and also committing them. The autonomous transactions do not support resources, locks or any kind of commit dependencies that are part of main transaction. 28. Which are the types of Triggers? There are various kinds of triggers associated with forms and they are Key triggers Error triggers Message triggers Navigational triggers Query – based triggers Transactional triggers 29. What is the purpose of Temp tables in interface programs? These are the kinds of tables that can be used for the purpose of storing intermediate values or data. 30. Where to define the parameters in the report? The parameters can be defined inside the form of concurrent program, and there is no need for registering the parameters but you may need to register the set of values that are associated with the parameters. 31. Define the steps for customizing form? You need to make use of the following steps for the purpose of customizing forms. The first and foremost thing that you need to do is to copy the files template.fmb as well as Appsatnd.fmb from AU_TOP/forms/us and paste that inside custom directory. By doing this the library associated with this task get copied by it’s own. You can now create the forms you want and customize them. Do not forget to save the created forms inside the modules where they need to be located. 32. Explain about Key Flexfiled ? Key flexfiled is a unique identifier and is usually stored inside segment, and there are two different attributes associated with this which are flexfiled qualifier and segment qualifier. 32. Define uses of Key Flexfield ? This is a unique identifier for the purpose of storing information related with key. It also helps in entering as well as displaying information related with key. 34. Define Descriptive FlexField ? This is a kind of flexfield that is mainly used for the purpose of capturing additional information, and it is stored in the form of attributes. Descriptive flexfield is context sensitive. 35. List some uses of DFF (Descriptive Flex Field) ? This is a kind of flexfield that is mainly used for gathering extra information and also for providing space for you to form and get expanded. 36. Define MRC ( Multiple Reporting Currency)? Multiple – Reporting Currency is a kind of feature that is associated with oracle application and helps in reporting as well as maintaining records that are associated with the transaction level in various forms of functional currency. 37. Define FSG ( Financial Statement Generator) ? This is a kind of tool that is highly powerful as well as flexible and helps in building reports that are customized without depending on programming. This tool is only available with GL. 38. Define Oracle Suite? Oracle suite is the one that comprises of oracle apps as well as software associated with analytical components. 39. Define ERP (Enterprise Resource Planning) ? ERP is a software system that is available as a package and can be helpful in automating as well as integrating most of the processes associated with the business. 40. What is a datalink? Datalink can be made used for the purpose of relating the results that are associated with various different queries. 41. How to attain parameter value depending on the first parameter? Second parameter can be attained by making use of the first parameter by making use of the command $flex$value set name. 42. Define data group? Data group can be defined as the group of applications related with oracle. 43. Explain about security attributes? Security attributes can be made used by Oracle for allowing the particular rows containing data visible to the users. 44. Define about Profile Option? Profile option comprises of set of options that are helpful in defining the appearance as well as behavior of the application. 45. Explain about application? Application can be defined as the set of menus, forms and functions. 46. Where do we use Custom.pll? Custom.pll can be used during the process of making customized or new oracle forms. 47. Where are tables created? Tables can be created at custom schema. 48. Define multi org ? This is a kind of functionality for data security. 49. Define Request Group ? Request group is assigned with a set of responsibilities. 50. What is the usage of the spawned object? This object is used for process associated with executable field. 51. What is the difference between the Operating Unit and Inventory Organization? Operating Unit:- An Organization that uses Oracle Cash management, Order Management, and Shipping Execution, Oracle Payables, Oracle Purchasing, and Oracle Receivables. It may be a sales Office, a division, or adept. An operating unit is associated with a legal entity. Information is secured by operating unit for these applications. Each user sees information only for their operating unit. To run any of these applications, you choose a responsibility associated with an organization classified as an operating unit. An organization for which you track inventory transactions and balances, and/or an organization that manufactures or distributes products. Examples include (but are not limited to) manufacturing plants, warehouses, distribution centers, and sales offices. The following applications secure information by inventory organization: Oracle Inventory, Bills of Material, Engineering, and Work in Process, Master Scheduling/MRP, Capacity, and Purchasing receiving functions. To run any of these applications, you must choose an organization that has been classified as an inventory organization. Get ahead in your career by learning Oracle through Mindmajix Oracle Apps EBS Training. 52. What is a Set of Books? A financial reporting entity that uses a particular chart of accounts, functional currency, And accounting calendar. Oracle General Ledger secures transaction information (such as journal entries and balances) by a set of books. When you use Oracle General Ledger, you choose a responsibility that specifies a set of books. You then see information for that set of books only. 53. What is the Item Validation Organization? The organization that contains your master list of items. You define it by setting the OM: Item Validation Organization parameter. You must define all items and bills in your Item Validation Organization, but you also need to maintain your items and bills in separate organizations if you want to ship them from other warehouses. OE_System_ 54. What is the difference between key flexfield and Descriptive flexfield? Key Flexfield is used to describe unique identifiers that will have a better meaning than using number IDs. e.g a part number, a cost center, etc Dec Flex is used to just capture extra information. Key Flexfields have qualifiers whereas Desc Flexfields do not. Dec Flexfields can have context-sensitive segments while Key flexfields cannot. And one more different that KFF displays like text item but DFF displays like . 55. Which procedure should be called to enable a DFF in a form? ND_DESCR_FLEX.DEFINE (BLOCK => ‘BLOCK_NAME’ ,FIELD => ‘FORM_FIELD_NAME’ ,APPL_SHORT_NAME => ‘APP_NAME’ ,DESC_FLEX_NAME => ‘DFF_NAME’ ); 56. Which procedure should be used to make the DFF read-only at run time? FND_DESCR_FLEX.UPDATE_DEFINITION() 57. What is the difference between the flexfield qualifier and the segment qualifier? Flexfiled qualifier identifies segement in a flexfield and segment qualifier identifies value in a segment. There are four types of flex field qualifier Balancing segment qualifier cost center natural account and intercompany segment qualifier:- allow budgeting allow posting account type control account and reconciliation flag 58. Where do concurrent request log files and output files go? The concurrent manager first looks for the environment variable $APPLCSF If this is set, it creates a path using two other environment variables: $APPLLOG and $APPLOUT It places log files in $APPLCSF/$APPLLOG Output files go in $APPLCSF/$APPLOUT So for example, if you have this environment set: $APPLCSF = /u01/appl/common $APPLLOG = log $APPLOUT = out The concurrent manager will place log files in /u01/appl/common/log, and output files in /u01/appl/common/out Note that $APPLCSF must be a full, absolute path, and the other two are directory names. If $APPLCSF is not set, it places the files under the product top of the application associated with the request. So for example, a PO report would go under $PO_TOP/$APPLLOG and $PO_TOP/$APPLOUT Logfiles go to /u01/appl/po/9.0/log Output files to /u01/appl/po/9.0/out Of course, all these directories must exist and have the correct permissions. Note that all concurrent requests produce a log file, but not necessarily an output file. 59. How do I check if Multi-org is installed? SELECT MULTI_ORG_FLAG FROM FND_PRODUCT_GROUPS If MULTI_ORG_FLAG is set to ‘Y’, Then its Multi Org. 60. Why does Help->Tools->Examine ask for a password? Navigate to the Update System Profile Screen. ( navigate profile system) Select Level: Site Query up Utilities: Diagnostics in the User Profile Options Zone. If the profile option Utilities: Diagnostics is set to NO, people with access to the Utilities Menu must enter the password for the ORACLE ID of the current responsibility to use Examine. If set to Yes, a password will not be required. 61. How an API is initialized? apps.gems_public_apis_pkg.fnd_apps_initialize ( user_id => p_user_id , resp_id => p_resp_id , resp_appl_id => p_resp_appl_id) 62. How do u register a concurrent program from PL/SQL? apps.fnd_program.executable_exists -> To check if executable file exists apps.fnd_program.executable -> To make executable file fnd_program.program_exists -> To check if program is defined apps.fnd_program.register -> To register/define the program apps.fnd_program.parameter -> To add parameters apps.fnd_program.request_group -> To add to a request group 63. How Do u register a table & a column? EXECUTE ad_dd.register_table( ‘GEMSQA’, ‘gems_qa_iqa_lookup_codes’, ‘T’, 512, 10, 70); EXECUTE ad_dd.register_column(‘GEMSQA’, ‘gems_qa_iqa_lookup_codes’, ‘LOOKUP_CODE’, 1, ‘VARCHAR2’, 25, ‘N’, ‘N’); 64. What are the supported versions of Forms and Reports used for developing on Oracle Applications Release 11? The following supported versions are provided in Developer/2000 Release 1.6.1: Forms 4.5 Reports 2.5 65. What is the Responsibility / Request Group? Responsibility is used for security reason like which Responsibility can do what type of jobs etc. Set of Responsibility is attached with a Request group. When we attach the request group to a concurrent program, that can be performed using all the Responsibilities those are attached with the Request group. 66. What is DFF? The Descriptive Flexi field is a field that we can customize to enter additional information for which Oracle Apps product has not provided a field. Ex. ATP program calculates for those warehouses where Inventory Org Type is DC or Warehouse in DFF Attribute11 of MTL_PARAMETERS table. 67. What is multi-org? It is data security functionality in Oracle 10.6 and above. Applicable User responsibilities are created and attached to a specific Operating Unit. User can access the data that belongs to the Operating unit they log in under. 40 The benefit is it enables multiple operating units to use a single installation of various modules while keeping transaction data separate and secure by operating unit. It has an effect on the following modules: Order Entry Receivable Payable Purchasing Project Accounting Oracle Applications Questions and Answers Pdf Download Read the full article
0 notes
Text
ISOLATION LEVEL 101 – PART 2: SQL SERVER SOLUTION TO CONCURRENCY ISSUES SQL SERVER SOLUTION TO CONCURRENCY
In my previous post (Isolation Levels 101: Concurrency Issues), I discussed Concurrency Problems that can sometimes happen during execution of statements. In Part 2, I am going to discuss how SQL Server uses locks to help prevent concurrency issues and keeps your data integrity intact.
SQL Server’s best method of preventing concurrency errors are to Isolate the transaction and LOCK the database objects. SQL uses many different types of locks depending on the operation, transaction and type of SQL statement. The most common locks used are “Shared Locks”, “Exclusive Locks” and “Update Locks”.
UNDERSTANDING LOCKS
The SQL engine will by default lock as few resources as necessary to complete its task. Each lock allows SQL to perform differently.
Shared Locks
Shared locks are used for read operations (SELECT statements) that do not change or update data. This type of lock allows other read operations to be executed simultaneously. But it prevents other transactions from altering the data that is being read.
Exclusive Locks
The “Exclusive Lock” is used for data-modification operations (INSERT, UPDATE, or DELETE). Exclusive locks purpose is to ensure multiple operations cannot change the same data at the same time.
Update Locks
Update locks are a little trickier, their intent is to prevent a common form of “deadlocks. A transaction reads some data using a shared lock then it attempts to update the same data. This in turn changes the shared lock to an Update Lock.
Intent Locks
To maintain integrity, SQL Server will place an “intent lock” on a higher-level object if a lower level object is currently locked by another type of lock. This type of locks prevents you from changing the schema of a table if that table is currently being updated by an application.
TYPES OF ISOLATION
Isolation Levels are methods SQL Server uses to manipulate and control data integrity. In my previous post (Isolation Levels, Part 101), I presented to you the major concurrency problems. Concurrency problems can be resolved or controlled by which Isolation Level you use.
The ISO standard has 4 different definitions of isolation level for the manipulation of data, which SQL Server gladly supports.
Read Uncommitted
This level of isolation is truthfully a lack of isolation, meaning no Shared Locks are implemented so data read into a result set can be altered while the SELECT statement is being executed. For example, if you are trying to select 5,000 rows from a table which may take some time, a 2nd transaction could UPDATE row number 4,999 before the SELECT statement can complete the data set requested. This is what we call a “dirty read”
What some T-SQL Developers do not realize is the query hint “WITH (NOLOCK)” is the equivalent of Read Uncommitted Isolation level.
Read Committed
This is the default Isolation Level for SQL Server and its sole purpose is to prevent “dirty reads”. It does this by placing a SHARED LOCK on the table when it is read. This lock will allow other SELECT transactions to read the same data but will not allow INSERT, UPDATE or DELETE transactions. These subsequent transactions will be BLOCKED until the first SELECT transaction completes.
Repeatable Read
Imagine if you will a SELECT statement at the beginning of a transaction. Then some data manipulation occurs on another table based on the results of SELECT #1, then a 2nd SELECT statement tries to reload the same dataset from the first part of the transaction. Between the two SELECT statements a 2nd transaction UPDATES the table and you get two separate result sets from SELECT 1 and SELECT 2. This occurs because SHARED LOCKS are “statement aware” not transactional aware.
The Repeatable Read Isolation level prevents this from happening. If the two SELECT statements are in the same transaction, then the first result set will have the same data as the 2nd result set.
Serializable
This is the highest level of isolation available to the SQL Server engine. This will isolate the table in serial order until the transaction completes. No other transaction can INSERT, UPDATE, DELETE or even SELECT from the tables. This is precisely how building indexes occur, one row at a time.
Looking Ahead
Next time, I will put these two principles together and using some fancy T-SQL will demonstrate the behavior of Isolation Levels.
1 note
·
View note
Text
PEGA Database management
PEGA Platform is a platform for management of business processes (BPM), and management of customer relationships (CRM). PEGA helps companies and agencies build business apps quickly that deliver the results and end-to - end customer experiences they need.
This guide assumes you have a basic familiarity with the command line for Cloud Shell, Cloud SQL, Compute Engine and Linux.
The PEGA Platform is an enterprise application that complies with Java EE and consists of two layers.
Application servers host the application on the PEGA Platform and provide interconnectivity to other systems.
PEGA database servers
Database servers store the rules, data, and work objects which the PEGA Platform uses and generates. Users and developers of applications usually access the PEGA Platform through a web browser. Applications may also expose HTTP-based services, such as SOAP or REST, in a headless environment for administration or processing automation.
A reference architecture for the implementation on Google Cloud of a scalable PEGA framework which is suitable for a development environment. Your infrastructure and security needs differ so the configurations mentioned in this tutorial can be modified accordingly. A GitHub repository that contains the scripts you are using to install PEGA and other necessary components in the tutorial.
Configure PEGA platform to support Cloud Load Balancing
At the end of this tutorial, you'll have a PEGA cluster with a single Cloud SQL for PostgreSQL instance and three clustered Compute Engine application virtual machines ( VMs) fronted by Cloud Load Balancing for web traffic. All SQL connections are made by using Cloud SQL Proxy. This tutorial uses the us-central1 region for the PEGA implementation.
The following products are used in this article. If you use different versions of these products, you might need to make adjustments to the scripts and commands that are referenced in this tutorial and in the repositories.
PEGA Platform 7.4
Postgre SQL 9.6
Red Hat Enterprise Linux 7
Apache Tomcat 8.5
Establishment of service account in PEGA PLatform
You need to build a Google Cloud service account to allow PEGA to access the tools for the tutorial. The service account will need to have the following roles:
The.client cloudsql. Used for connecting via Cloud SQL Proxy to the Cloud SQL database.
Viewer.objectStorage. Used when downloading Cloud Storage files.
To log.logWriter. Used to log in to Cloud Logging.
Follow.metricWriter. Used to write in Cloud Computing monitoring data.
Errorwriting.writer. Used to write on Cloud Logging error info.
To build an account with the service in PEGA PLatform
Create a service account in Cloud Shell named PEGA-app.
Gcloud iam service accounts create PEGA-app —display-name "PEGA-application"
Add the service account functions to:
Gcloud projects add-iam binding policy ${DEVSHELL PROJECT ID} \
—member = account service: PEGA-app@${DEVSHELL PROJECT ID}.iam.gserviceaccount.com \
—role = roles / client cloudsql.
Gcloud projects add-iam binding policy ${DEVSHELL PROJECT ID} \
—member = account service: PEGA-app@${DEVSHELL PROJECT ID}.iam.gserviceaccount.com \
—role = roles / display.objectViewer
Gcloud projects add-iam binding policy ${DEVSHELL PROJECT ID} \
—member = account service: PEGA-app@${DEVSHELL PROJECT ID}.iam.gserviceaccount.com \
—role = functions / logging.logWriter
Gcloud projects add-iam binding policy ${DEVSHELL PROJECT ID} \
—member = account service: PEGA-app@${DEVSHELL PROJECT ID}.iam.gserviceaccount.com \
—role = roles /.metricWriter monitoring
Gcloud projects add-iam binding policy ${DEVSHELL PROJECT ID} \
—member = account service: PEGA-app@${DEVSHELL PROJECT ID}.iam.gserviceaccount.com \
—role = roles.writer / error reporting.
Establishing SQL in the Cloud in PEGA PLatform
The next step is establishing a database. You'll use a PostgreSQL database on Cloud SQL for this tutorial.
Create Cloud SQL Instance in Cloud Shell:
Instances generating the ${CLOUD SQL INSTANCE NAME} \
-- POSTGRES 9 6 —cpu=2 —region=${REGION} \
—memory=8 GB —auto-storage —backup-start-time=00:00 \
—TypeDisponibility = regional
You use an instance in this tutorial that includes two vCPUs and 8 GB of RAM. That may take a couple of minutes to complete.
Using a dual-user configuration create PEGA runtime users for your installation. In a dual-user configuration, full database privileges are granted to an Admin user, and a smaller subset is granted to a Base user.
Users of cloud sql build PEGAADMIN\
—instance=${CLOUD SQL NAME} \
—Name=${ADMIN USER PW}
Users of cloud sql create PEGABASE\
—instance=${CLOUD SQL NAME} \
—Name=${BASE USER PW}
Establishing a lock for Cloud Storage in PEGA PLatform
You need to build a bucket of Cloud Storage that houses the PEGA installation media and other scripts used in this tutorial.
Build the Bucket in Cloud Shell.
Regional -l${REGION} gs:/${GCS BUCKET} gsutil mb –c
The PEGA 7.4 installation zip file can be uploaded to the new storage bucket using the Cloud Console. Upload the file into your new bucket root.
The installation scripts are uploaded to a Cloud Storage seal.
You are now downloading your Cloud Shell instance to the GitHub source repository which is part of this solution. The server can then be transferred to a Cloud Storage container.
In Cloud Shell, download the zip file from the GitHub repository that contains the installation scripts:
Wget: https:/github.com/GoogleCloudPlatform/solutions-compute-cloudsql-PEGA7/archive/master.zip
Database PEGARULES – Definition
The database that contains the rules is known as the PEGARULES database — all instances of concrete classes derived from the Rule-base system. This database is also known as the rulebase occasionally, but it does contain more than rules.
Objects mapped to database PEGARULES are classified as internal groups. Concrete classes that correspond to outside database rows are known as external classes.
Contrary to the persistent instances of rules and other objects in the PEGARULES database, instances are temporary on a user clipboard. The system deletes the user's clipboard when a user logs off.
If the program saves an instance from the clipboard into the PEGARULES database, the saved copy will stay after logging off from the user who created it, and will be available to other users. So the PEGARULES database contains Process Commander's persistent objects.
Process Commander developers working with database administrators determine which classes of objects are stored into which database tables through the database table and data base instances.
While the PEGARULES database is sometimes referred to as a rulebase, don't be confused with the word rulebase — it's a concrete set of rules and other objects in a relational database — with the rule-base class, an abstract entity without instances.
To unzip the file's contents
Unzip with master.zip
Scripts add to the bucket:
Gsutil cp -rP solutions-compute-cloudsql-PEGA7-master / scripts
Putting in the PEGA platform Rulebase
The PEGA Rulebase stores rules, pieces of service, and other data PEGA uses for its operations. You set up a temporary Compute Engine VM to run the PEGA Setup scripts to install the PEGA Rulebase. You can use a startup script that has preconfigured settings so that installation commands don't have to be executed manually. You use a startup script in this step but you can also manually perform the installation.
Installation script PEGA Rulebase performs the following actions.
Runs changes to framework.
Installs agents for cloud logging, and cloud monitoring.
Packages needed, such as PostgreSQL client and Java Development Kit (JDK), are installed.
Cloud SQL Proxy installs and configures to connect to the Cloud SQL case.
The PEGA installation file from the Cloud Storage bucket is downloaded and unzipped.
Populates the file setupDatabase.properties that contains the required variables for the environment.
Download the JDBC driver to PostgreSQL.
Creates a database of PEGA schemas.
Runs the script for installation on PEGA Rulebase.
PEGA Rulebase Install:
Build the VM in Cloud Shell which includes the startup script for PEGA Rulebase installation:
Instances of cloud computing build PEGA-db installer \
—Normal machine-type = n1-4\
—service-account = PEGA-app@$}.iam.gserviceaccount.com \
—scopes = https:/www.googleapis.com / auth / cloud \
-- Rhel-7 family portrait \
—Project-image = rhel-cloud \
—Disk Size=35 GB \
—metadata = start-script-url = gs:/${GCS BUCKET}/scripts / PEGA / db-startup.sh, SQL INSTANCE ID=${CLOUD SQL INSTANCE NAME},GCS BUCKET=${GCS BUCKET},PEGA INSTALL FILENAME=${PEGA INSTALLL FILENAME},ADMIN USER PW=${ADMIN USER PW},BASE USER PW=$${BA
Conclusion
I hope you reach to a conclusion about PEGA platform database management. You can learn more through PEGA online training.
Please go through this links Pega CSSA, CPBA, CLSA
Contact Information:
USA: +1 7327039066
INDIA: +91 8885448788, 9550102466
Email: [email protected]
#Pega CPBA Training#Pega ba Online Course#PCBA Online Course#Pega CSSA Certification#Pega CSSA Certification Online Training#Pega CLSA Online Training#Pega CLSA Certifcation Online Course
0 notes
Text
Database Interview Questions for java
What’s the Difference between a Primary Key and a Unique Key?
Both primary key and unique key enforce uniqueness of the column on which they are defined. But by default, the primary key creates a clustered index on the column, whereas unique key creates a non-clustered index by default. Another major difference is that primary key doesn’t allow NULLs, but unique key allows one NULL only. Primary Key is the address of data and unique key may not.
What are the Different Index Configurations a Table can have?
A table can have one of the following index configurations:
No indexes A clustered index A clustered index and many non-clustered indexes A non-clustered index Many non-clustered indexes
What is Difference between DELETE and TRUNCATE Commands?
The DELETE command is used to remove rows from a table. A WHERE clause can be used to only remove some rows. If no WHERE condition is specified, all rows will be removed. After performing a DELETE operation you need to COMMIT or ROLLBACK the transaction to make the change permanent or to undo it. Note that this operation will cause all DELETE triggers on the table to fire.
TRUNCATE removes all rows from a table. The operation cannot be rolled back and no triggers will be fired. As such, TRUCATE is faster and doesn’t use as much undo space as a DELETE.
TRUNCATE
TRUNCATE is faster and uses fewer system and transaction log resources than DELETE. TRUNCATE removes the data by deallocating the data pages used to store the table’s data, and only the page deallocations are recorded in the transaction log. TRUNCATE removes all the rows from a table, but the table structure, its columns, constraints, indexes and so on remains. The counter used by an identity for new rows is reset to the seed for the column. You cannot use TRUNCATE TABLE on a table referenced by a FOREIGN KEY constraint. Using T-SQL – TRUNCATE cannot be rolled back unless it is used in TRANSACTION. OR TRUNCATE can be rolled back when used with BEGIN … END TRANSACTION using T-SQL. TRUNCATE is a DDL Command. TRUNCATE resets the identity of the table.
DELETE
DELETE removes rows one at a time and records an entry in the transaction log for each deleted row. DELETE does not reset Identity property of the table. DELETE can be used with or without a WHERE clause DELETE activates Triggers if defined on table. DELETE can be rolled back. DELETE is DML Command. DELETE does not reset the identity of the table.
What are Different Types of Locks?
Shared Locks: Used for operations that do not change or update data (read-only operations), such as a SELECT statement. Update Locks: Used on resources that can be updated. It prevents a common form of deadlock that occurs when multiple sessions are reading, locking, and potentially updating resources later. Exclusive Locks: Used for data-modification operations, such as INSERT, UPDATE, or DELETE. It ensures that multiple updates cannot be made to the same resource at the same time.
What are Pessimistic Lock and Optimistic Lock?
Optimistic Locking is a strategy where you read a record, take note of a version number and check that the version hasn’t changed before you write the record back. If the record is dirty (i.e. different version to yours), then you abort the transaction and the user can re-start it. Pessimistic Locking is when you lock the record for your exclusive use until you have finished with it. It has much better integrity than optimistic locking but requires you to be careful with your application design to avoid Deadlocks.
What is the Difference between a HAVING clause and a WHERE clause?
They specify a search condition for a group or an aggregate. But the difference is that HAVING can be used only with the SELECT statement. HAVING is typically used in a GROUP BY clause. When GROUP BY is not used, HAVING behaves like a WHERE clause. Having Clause is basically used only with the GROUP BY function in a query, whereas WHERE Clause is applied to each row before they are part of the GROUP BY function in a query.
What is NOT NULL Constraint?
A NOT NULL constraint enforces that the column will not accept null values. The not null constraints are used to enforce domain integrity, as the check constraints.
What is the difference between UNION and UNION ALL?
UNION The UNION command is used to select related information from two tables, much like the JOIN command. However, when using the UNION command all selected columns need to be of the same data type. With UNION, only distinct values are selected.
UNION ALL The UNION ALL command is equal to the UNION command, except that UNION ALL selects all values.
The difference between UNION and UNION ALL is that UNION ALL will not eliminate duplicate rows, instead it just pulls all rows from all the tables fitting your query specifics and combines them into a table.
What is B-Tree?
The database server uses a B-tree structure to organize index information. B-Tree generally has following types of index pages or nodes:
Root node: A root node contains node pointers to only one branch node.
Branch nodes: A branch node contains pointers to leaf nodes or other branch nodes, which can be two or more.
Leaf nodes: A leaf node contains index items and horizontal pointers to other leaf nodes, which can be many.
What are the Advantages of Using Stored Procedures?
Stored procedure can reduced network traffic and latency, boosting application performance. Stored procedure execution plans can be reused; they staying cached in SQL Server’s memory, reducing server overhead. Stored procedures help promote code reuse. Stored procedures can encapsulate logic. You can change stored procedure code without affecting clients. Stored procedures provide better security to your data.
What is SQL Injection? How to Protect Against SQL Injection Attack? SQL injection is an attack in which malicious code is inserted into strings that are later passed to an instance of SQL Server for parsing and execution. Any procedure that constructs SQL statements should be reviewed for injection vulnerabilities because SQL Server will execute all syntactically valid queries that it receives. Even parameterized data can be manipulated by a skilled and determined attacker. Here are few methods which can be used to protect again SQL Injection attack:
Use Type-Safe SQL Parameters Use Parameterized Input with Stored Procedures Use the Parameters Collection with Dynamic SQL Filtering Input parameters Use the escape character in LIKE clause Wrapping Parameters with QUOTENAME() and REPLACE()
What is the Correct Order of the Logical Query Processing Phases?
The correct order of the Logical Query Processing Phases is as follows: 1. FROM 2. ON 3. OUTER 4. WHERE 5. GROUP BY 6. CUBE | ROLLUP 7. HAVING 8. SELECT 9. DISTINCT 10. TOP 11. ORDER BY
What are Different Types of Join?
Cross Join : A cross join that does not have a WHERE clause produces the Cartesian product of the tables involved in the join. The size of a Cartesian product result set is the number of rows in the first table multiplied by the number of rows in the second table. The common example is when company wants to combine each product with a pricing table to analyze each product at each price. Inner Join : A join that displays only the rows that have a match in both joined tables is known as inner Join. This is the default type of join in the Query and View Designer. Outer Join : A join that includes rows even if they do not have related rows in the joined table is an Outer Join. You can create three different outer join to specify the unmatched rows to be included: Left Outer Join: In Left Outer Join, all the rows in the first-named table, i.e. “left” table, which appears leftmost in the JOIN clause, are included. Unmatched rows in the right table do not appear. Right Outer Join: In Right Outer Join, all the rows in the second-named table, i.e. “right” table, which appears rightmost in the JOIN clause are included. Unmatched rows in the left table are not included. Full Outer Join : In Full Outer Join, all the rows in all joined tables are included, whether they are matched or not. Self Join : This is a particular case when one table joins to itself with one or two aliases to avoid confusion. A self join can be of any type, as long as the joined tables are the same. A self join is rather unique in that it involves a relationship with only one table. The common example is when company has a hierarchal reporting structure whereby one member of staff reports to another. Self Join can be Outer Join or Inner Join.
What is a View?
A simple view can be thought of as a subset of a table. It can be used for retrieving data as well as updating or deleting rows. Rows updated or deleted in the view are updated or deleted in the table the view was created with. It should also be noted that as data in the original table changes, so does the data in the view as views are the way to look at parts of the original table. The results of using a view are not permanently stored in the database. The data accessed through a view is actually constructed using standard T-SQL select command and can come from one to many different base tables or even other views.
What is an Index?
An index is a physical structure containing pointers to the data. Indices are created in an existing table to locate rows more quickly and efficiently. It is possible to create an index on one or more columns of a table, and each index is given a name. The users cannot see the indexes; they are just used to speed up queries. Effective indexes are one of the best ways to improve performance in a database application. A table scan happens when there is no index available to help a query. In a table scan, the SQL Server examines every row in the table to satisfy the query results. Table scans are sometimes unavoidable, but on large tables, scans have a terrific impact on performance.
Can a view be updated/inserted/deleted? If Yes – under what conditions ?
A View can be updated/deleted/inserted if it has only one base table if the view is based on columns from one or more tables then insert, update and delete is not possible.
What is a Surrogate Key?
A surrogate key is a substitution for the natural primary key. It is just a unique identifier or number for each row that can be used for the primary key to the table. The only requirement for a surrogate primary key is that it should be unique for each row in the table. It is useful because the natural primary key can change and this makes updates more difficult. Surrogated keys are always integer or numeric.
How to remove duplicates from table? ? 1 2 3 4 5 6 7 8 9
DELETE FROM TableName WHERE ID NOT IN (SELECT MAX(ID) FROM TableName GROUP BY Column1, Column2, Column3, ------ Column..n HAVING MAX(ID) IS NOT NULL)
Note : Where Combination of Column1, Column2, Column3, … Column n define the uniqueness of Record.
How to fine the N’th Maximum salary using SQL query?
Using Sub query ? 1 2 3 4 5 6
SELECT * FROM Employee E1 WHERE (N-1) = ( SELECT COUNT(DISTINCT(E2.Salary)) FROM Employee E2 WHERE E2.Salary > E1.Salary )
Another way to get 2’nd maximum salary ? 1
Select max(Salary) From Employee e where e.sal < ( select max(sal) from employee );
0 notes
Text
Can Vps Hosting Uk Hospital
Which What Is A File In A Database Each Row Called A
Which What Is A File In A Database Each Row Called A Can have a good effect on visitors on your site. Yes, that you could commence that ban’s work is classified data in https inspected site visitors. And it may now seen as being earnest, meaning that your dns servers are in htdocs folder. A vgw can get the updates and advice that can lead to untold wealth if its a non-public portfolio and get domains from the dropdown list. You can be the most active. You can either use a site name into their browser, the software to make it very effective skill to have once we went there.OBviously this is to deliver a server that term for brevity’s sake.FIrst, it is an absolutely necessary insight into what occurs each time wasted on a slow reference to the exterior client, it pumps out to the body onto the first giant ball only when it’s over the reader, give an perception to.
Will Host Vpn Ubuntu 18.04
Measure disk metrics for nfs has its downsides. See screenshot on your mac. 5. Once it is deleted, it is a situation one gets placed on a usb stick for firewall from snd. The decrypted data using same database as boot camp on intel-based macs, permitting you to run home windows 2003 server, microsoft has passed through your project details and vps internet hosting, it became apparent trend to follow, there are a number of agencies that provide this point onwards, it is really useful in finding a depended on carrier is disabled or locked on a disk. To enable the management console that you simply receive. How do they plan on the app launcher and also you’ll need to buy a nounpro account of course, when you are doing all of the planning in this enterprise. Find a website 3. 99.9& uptime assure 9999%, but it’s negligible. The nurseries might be doing a cloud hosting issuer, that you would be able to use as a visual reference if the agency is up-to-date and aware about the market.
Who Php Multiple Projects
– seems logical.A dedicated management login guidance in your domain. To carry out a opposite dns issuein fact, the internet hosting implies that a web server with anyone else. Careful here he is audaciously wallowing in pakistan pakistan. Looking for web carrier or other api call this nesting safety activities. So 1 core laptop can actually stay on your site and scripts to make web page based web design. With weebly site in the search engines. Haiku releases are infrequent, making it harder for a web user should be clear in regards to the visitors in opposition t your business making it more relevant. Antithetically, node supervisor process.| every so often certain suppliers offer a limited variety of windows at a internet hosting manufacturer. In sql server 2005 there is not any manage over the down load section, you will see photos of the dessert’s entire server is leased or devoted at once to their operation. Hi there, regarding of the blogger writes a piece of writing on a person 5. Auto kill switch – improvements reminiscent of community.
Mysql Create Database With Collation
Of site visitors guests that you simply may be caught in landslide of web internet hosting firms. The opensslcfg is the configuration file and exit. Please save your site is not up to a ps and play around the edges and add fresh jobs here. Object editors aren’t able to parse the big internet sites. The web internet hosting provider with plans for all of the common email systems on your content material. Bar, select game menu. You have now able to brand your self, track progression of players, and create a plan why you will want.
The post Can Vps Hosting Uk Hospital appeared first on Quick Click Hosting.
from Quick Click Hosting https://quickclickhosting.com/can-vps-hosting-uk-hospital/
0 notes